Trapit : 学習機能でユーザーの嗜好にあった情報を収集するウェブキュレーション
Trapit

Trapitはユーザーの求める最新の情報を自動で収集してくれるキュレーションツール。
独自の学習機能でネット上に散在する無数の情報の中から興味のある情報をピックアップしてきてくれる興味深いサービスです。
アカウントを作成したら、まずは"Trap"を作成します。
ここでいう"Trap"というのは情報のカテゴリーを意味し、『Discover』から自分の興味のあるキーワードを指定します。
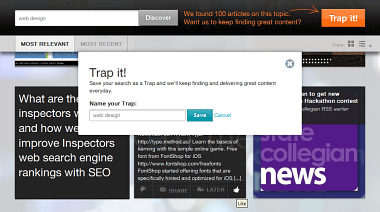
『Featured Traps』にはあらかじめいくつかのカテゴリが用意されているので、そこから興味のあるものを自分のTrapに追加することもできます。
何らかのTrapを作るとそれに関連した情報を自動で集めてきてとりあえず表示されますが、ここからがこのサービスの特徴的なところです。
この段階ではあくまで一般的なTrapであり、まだその情報群が本当にユーザーの嗜好にあったものとは限りません。
そこで提示されたTrapに対して、『Like』か『Dislike』かを判定してやります。
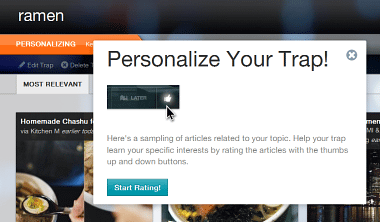
これを5,6回繰り返せば学習機能が働いてあなたの嗜好にあったTrapが生成されるという仕組みです。
ちょうどインターネットラジオで有名なLast.fmやPANDORAのように再生されるに対して"好き嫌い"を送信することで、ユーザーの好みを判断して自動的に好きそうな曲をかけるというアレと原理は同じです。
ネット上に流れる最新の情報ストリームから作成したパーソナルなTrapに引っかかった情報が次々と表示されていき、ユーザーはそれらをチェックしながら元記事を閲覧したり、情報をシェアしたりすることができます。
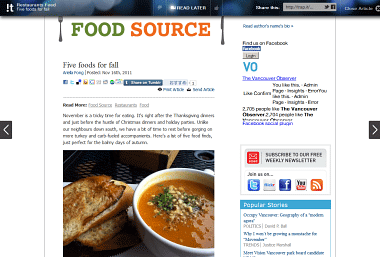
もちろん『Like/Dislike』を継続して行うことで、より限定的で個人的なTrapに改善されていくことになります。
また、こちらのサービスのウリの一つでもあるのが情報の鮮度で、更新が非常に高頻度で行われるのが特徴です。
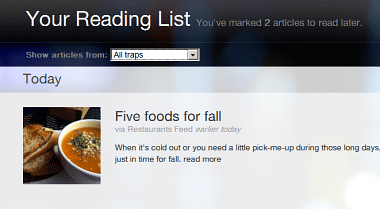
"これは!"と思った情報はとりあえず『LATER』をクリックして『Reading List』にストックしておくと、情報の取りこぼしがありません。
さて、ユニークで興味深いこちらのサービスですが、ひとつ残念なのがキーワード入力に日本語が通らないことです。
英語で入力してTrapを作成すれば必然的に収集される情報は英語圏のものとなるため、日本のローカルな情報を求めるユーザーにとってはあまり使えるサービスではないでしょう。
ただ、こういった手法を使った嗜好性キュレーターのようなサービスはアイデアとして斬新で、今後国内でも真似をするサービスが現れるかもしれません。









