2009 . 05 . 23
Free OCR : PDFやイメージからテキストを抽出できるオンラインOCR
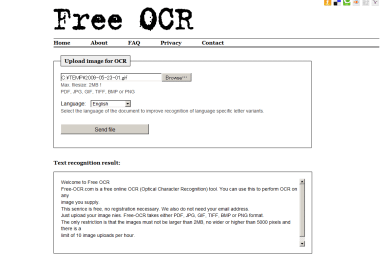
PDFやイメージの中ののテキスト部分を解析して、テキストデータとして抽出できるオンラインOCRサービス。
読み込めるファイルフォーマットははPDF, JPG, GIF, TIFF, BMP, PNG。
また画像は、2Mbで縦横5000ピクセル、一時間に10ファイルまでという制限があります。
解析精度は解像度によりますが、単純な英語であれば72dpi程度でも、かなりの精度で変換できるようです。
- 残念ですが、日本語には対応していません









